Copyright 2024-2026, MASSACHUSETTS INSTITUTE OF TECHNOLOGY
Subject to FAR 52.227-11 – Patent Rights – Ownership by the Contractor (May 2014).
SPDX-License-Identifier: MIT
Torchvision Object Detection Example#
The MAITE library provides interfaces for AI components such as datasets, models, metrics, and augmentations to make their use more consistent across test and evaluation (T&E) tools and workflows.
In this tutorial, you will use MAITE in conjunction with a set of common libraries to:
Wrap an object detection dataset from Torchvision (COCO),
Wrap an object detection model from Torchvision (Faster RCNN),
Wrap a metric from Torchmetrics (mean average precision),
Compute performance on the clean dataset using MAITE’s
evaluateutility,Wrap an augmenation from Kornia (Gaussian noise), and
Compute performance on the perturbed dataset using
evaluate.
Once complete, you will have a basic understanding of MAITE’s interfaces for datasets, models, metric, and augmentations, as well as how to use MAITE’s native API for running evaluations.
This tutorial does not assume any prior knowledge, but some experience with Python, machine learning, and the PyTorch framework may be helpful. Portions of code are adapted from the object detection example in the Torchvision documentation.
Getting Started#
This tutorial uses MAITE, PyTorch, Torchvision, Torchmetrics, Kornia, and Matplotlib. You can use the following commands to create a conda environment with these dependencies:
conda create --name torchvision_obj_det python=3.10
conda activate torchvision_obj_det
pip install maite jupyter torch torchvision torchmetrics pycocotools kornia watermark
Now that we’ve created an environment, we import the necessary libraries:
from __future__ import annotations
import json
from dataclasses import dataclass
from pathlib import Path
from typing import Any, Sequence
import kornia.augmentation as K
import matplotlib.pyplot as plt
import requests
import torch
from PIL import Image
from torchmetrics import Metric as tmMetric
from torchmetrics.detection.mean_ap import MeanAveragePrecision
from torchvision.datasets import CocoDetection
from torchvision.models.detection import (
FasterRCNN_ResNet50_FPN_V2_Weights,
fasterrcnn_resnet50_fpn_v2,
)
from torchvision.ops.boxes import box_convert
from torchvision.transforms.functional import pil_to_tensor, to_pil_image
from torchvision.utils import draw_bounding_boxes
import maite.protocols.object_detection as od
from maite.interop.torchmetrics import TMDetectionMetric
from maite.protocols import (
ArrayLike,
AugmentationMetadata,
DatasetMetadata,
DatumMetadata,
MetricMetadata,
ModelMetadata,
)
from maite.tasks import evaluate
%load_ext watermark
%watermark -iv -v
Python implementation: CPython
Python version : 3.12.13
IPython version : 9.12.0
PIL : 12.1.1
json : 2.0.9
kornia : 0.8.2
maite : 0.9.5
matplotlib : 3.10.8
requests : 2.33.0
torch : 2.11.0
torchmetrics: 1.9.0
torchvision : 0.26.0
Wrapping a Torchvision Dataset#
We’ll be wrapping Torchvision’s CocoDetection dataset, which provides support for the COCO object detection dataset.
In order to make this tutorial faster to run and not require a large download, we’ve provided a modified annotations JSON file from the validation split of the COCO 2017 object detection dataset containing only the first 4 images (and will dynamically download only those images using the “coco_url”).
Note that the COCO annotations are licensed under a Creative Commons Attribution 4.0 License (see COCO terms of use).
Native Dataset#
First we download the first 4 images of the validation split:
def download_images(coco_json_subset: dict[str, Any], root: str | Path):
root = Path(root)
root.mkdir(parents=True, exist_ok=True)
for image in coco_json_subset["images"]:
url = image["coco_url"]
filename = Path(root) / image["file_name"]
if filename.exists():
print(f"skipping {url}")
else:
print(f"saving {url} to {filename} ... ", end="")
r = requests.get(url)
with open(filename, "wb") as f:
f.write(r.content)
print("done")
COCO_ROOT = Path("coco_val2017_subset")
ann_subset_file = COCO_ROOT / "instances_val2017_first4.json"
coco_subset_json = json.load(open(ann_subset_file, "r"))
download_images(coco_subset_json, root=COCO_ROOT)
saving http://images.cocodataset.org/val2017/000000397133.jpg to coco_val2017_subset/000000397133.jpg ...
done
saving http://images.cocodataset.org/val2017/000000037777.jpg to coco_val2017_subset/000000037777.jpg ...
done
saving http://images.cocodataset.org/val2017/000000252219.jpg to coco_val2017_subset/000000252219.jpg ...
done
saving http://images.cocodataset.org/val2017/000000087038.jpg to coco_val2017_subset/000000087038.jpg ...
done
Next we create the Torchvision dataset and verify that its reduced length is 4:
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
len(tv_dataset) = 4
Each item of the dataset contains an image along with a list of
annotation dictionaries. The bounding box (bbox) format is “xywh”
and the category_id is one of COCO’s 90 categories (each of which
has a name and a supercategory).
# Get first image and its annotations
img, annotations = tv_dataset[0]
# Explore structure
print(f"{type(img) = }")
print(f"{type(annotations) = }")
print(f"{type(annotations[0]) = }")
print(f"{len(annotations[0]) = }")
print(f"{annotations[0].keys() = }")
print(f"{annotations[0]['bbox'] = }")
print(f"{annotations[0]['category_id'] = }")
print(f"{tv_dataset.coco.cats[64] = }")
type(img) = <class 'PIL.Image.Image'>
type(annotations) = <class 'list'>
type(annotations[0]) = <class 'dict'>
len(annotations[0]) = 7
annotations[0].keys() = dict_keys(['segmentation', 'area', 'iscrowd', 'image_id', 'bbox', 'category_id', 'id'])
annotations[0]['bbox'] = [102.49, 118.47, 7.9, 17.31]
annotations[0]['category_id'] = 64
tv_dataset.coco.cats[64] = {'supercategory': 'furniture', 'id': 64, 'name': 'potted plant'}
Wrapped Dataset#
In order to facilitate executing T&E workflows with datasets from
difference sources (e.g., existing libraries like Torchvision or Hugging
Face or custom datasets), MAITE provides a Dataset protocol that
specifies the expected interface (i.e, a minimal set of required
attributes, methods, and method type signatures).
At a high level, a MAITE object detection Dataset needs to have two
methods (__len__ and __getitem__) and return the image, target
(label/class), and metadata associated with a requested dataset index.
Note: the Dataset-implementing class should raise an IndexError when
__getitem__ is called with indices beyond container bounds; this
permits python to create a default __iter__ implementation on
objects implementing the Dataset protocol. Alternatively, users may
directly implement their own __iter__ method to support iteration.
The following wrapper internally converts from the “native” format of the dataset to types compatible with MAITE:
@dataclass
class CocoDetectionTarget:
boxes: torch.Tensor
labels: torch.Tensor
scores: torch.Tensor
# Get mapping from COCO category to name
index2label = {k: v["name"] for k, v in tv_dataset.coco.cats.items()}
class MaiteCocoDetection:
metadata: DatasetMetadata = {"id": "COCO Detection Dataset"}
# We can optionally include index2label mapping within DatasetMetadata
metadata: DatasetMetadata = {**metadata, "index2label": index2label}
def __init__(self, dataset: CocoDetection):
self._dataset = dataset
def __len__(self) -> int:
return len(self._dataset)
def __getitem__(
self, index: int
) -> tuple[ArrayLike, CocoDetectionTarget, DatumMetadata]:
try:
# get original data item
img_pil, annotations = self._dataset[index]
except IndexError as e:
# Here the underlying dataset is raising an IndexError since the index is beyond the
# container's bounds. When wrapping custom datasets, wrappers are responsible to for
# raising an IndexError in `__getitem__` when an index exceeds the container's bounds;
# this enables iteration on the wrapper to properly terminate.
print(
f"The index number {index} is out of range for the dataset which has length {len(self._dataset)}"
)
raise (e)
# format input
img_pt = pil_to_tensor(img_pil)
# format ground truth
num_boxes = len(annotations)
boxes = torch.zeros(num_boxes, 4)
for i, ann in enumerate(annotations):
bbox = torch.as_tensor(ann["bbox"])
boxes[i, :] = box_convert(bbox, in_fmt="xywh", out_fmt="xyxy")
labels = torch.as_tensor([ann["category_id"] for ann in annotations])
scores = torch.ones(num_boxes)
# format metadata
datum_metadata: DatumMetadata = {
"id": self._dataset.ids[index],
}
return img_pt, CocoDetectionTarget(boxes, labels, scores), datum_metadata
We now create a wrapped version of the dataset that conforms to the MAITE protocol.
Note that the dataset variable has od.Dataset as the type hint.
If your environment has a static type checker enabled (e.g., the Pyright
type checker via the Pylance language server in VS Code), then the type
checker will verify that our wrapped dataset conforms to the protocol
and indicate a problem if not (e.g., by underlining with a red
squiggle).
dataset: od.Dataset = MaiteCocoDetection(tv_dataset)
len(dataset)
4
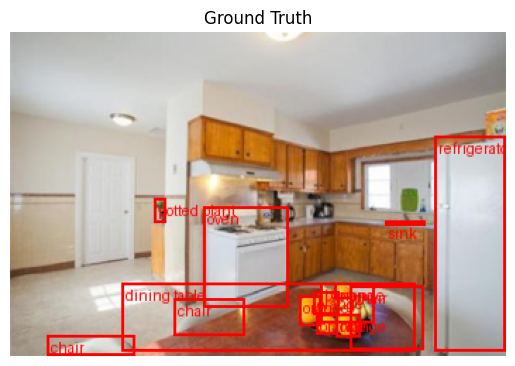
Next we’ll display a sample image along with the ground truth annotations.
def create_pil_image(
input: ArrayLike,
target: od.ObjectDetectionTarget,
index2label: dict[int, str],
color: str = "red",
) -> Image.Image:
img_pt = torch.as_tensor(input)
boxes = torch.as_tensor(target.boxes)
label_ids = torch.as_tensor(target.labels)
label_names = [index2label[int(id.item())] for id in label_ids]
box = draw_bounding_boxes(
img_pt, boxes=boxes, labels=label_names, colors=color, width=2
)
return to_pil_image(box.detach())
# Get mapping from COCO category to name
index2label = {k: v["name"] for k, v in tv_dataset.coco.cats.items()}
# Get sample image and overlay ground truth annotations (bounding boxes)
i = 0
input, target, _ = dataset[i]
img = create_pil_image(input, target, index2label)
fig, ax = plt.subplots()
ax.axis("off")
ax.set_title("Ground Truth")
ax.imshow(img);
Wrapping a Torchvision Model#
In this section, we’ll wrap a Torchvision object detection model that’s been pretrained on the COCO dataset.
First we create the “native” Torchvision model with a specified set of pretrained weights:
weights = FasterRCNN_ResNet50_FPN_V2_Weights.DEFAULT
tv_model = fasterrcnn_resnet50_fpn_v2(
weights=weights, box_score_thresh=0.9, progress=False
)
Next we wrap the model to conform to the MAITE od.Model protocol,
which requires a __call__ method that takes a batch of inputs and
returns a batch of predictions:
class TorchvisionDetector:
def __init__(
self,
model: torch.nn.Module,
metadata: ModelMetadata,
transforms: Any,
device: str,
):
self.model = model
self.metadata = metadata
self.transforms = transforms
self.device = device
self.model.eval()
self.model.to(device)
def __call__(self, batch: Sequence[ArrayLike]) -> Sequence[CocoDetectionTarget]:
# convert to list of tensors, transfer to device, and apply inference transforms
# - https://pytorch.org/vision/stable/models.html
# - "The models expect a list of Tensor[C, H, W]."
tv_input = [
self.transforms(torch.as_tensor(b_elem)).to(self.device) for b_elem in batch
]
# get predictions
tv_predictions = self.model(tv_input)
# reformat output
predictions = [
CocoDetectionTarget(
p["boxes"].detach().cpu(),
p["labels"].detach().cpu(),
p["scores"].detach().cpu(),
)
for p in tv_predictions
]
return predictions
model: od.Model = TorchvisionDetector(
model=tv_model,
metadata={"id": "TorchvisionDetector", "index2label": index2label},
transforms=weights.transforms(),
device="cpu",
)
For an initial test, we’ll manually create an input batch and perform inference on it with the wrapped model:
# Create batch with sample image
i = 0
x, y, md = dataset[i]
x = torch.as_tensor(x)
xb, yb, mdb = x.unsqueeze(0), [y], [md]
print(f"{xb.shape = }")
# Get predictions for batch(which just has one image for this example)
preds = model([xb[0]])
# Overlay detections on image
img = create_pil_image(xb[0], preds[0], index2label)
# Plot
fig, ax = plt.subplots()
ax.axis("off")
ax.set_title("Prediction")
ax.imshow(img);
xb.shape = torch.Size([1, 3, 230, 352])
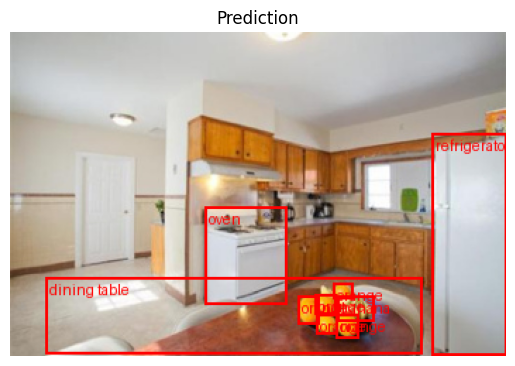
Qualitatively, it appears that the model has detected the majority of the objects, but not all.
At this point, we’d like to perform a more quantitative evaluation across a larger set of images.
Metrics#
In this section we wrap a Torchmetrics object detection metric to
conform to the MAITE od.Metric protocol.
First we create a “native” Torchmetrics mean average prediction (mAP) metric:
tm_metric = MeanAveragePrecision(
box_format="xyxy",
iou_type="bbox",
iou_thresholds=[0.5],
rec_thresholds=[0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0],
max_detection_thresholds=[1, 10, 100],
class_metrics=False,
extended_summary=False,
average="macro",
)
Next we wrap the metric as a MAITE od.Metric that has the required
update, compute, and reset methods:
class WrappedTorchmetricsMetric:
def __init__(self, tm_metric: tmMetric, metadata: MetricMetadata):
self._tm_metric = tm_metric
self.metadata = metadata
# Create utility function to convert ObjectDetectionTarget_impl type to what
# the type expected by torchmetrics IntersectionOverUnion metric
@staticmethod
def to_tensor_dict(target: od.ObjectDetectionTarget) -> dict[str, torch.Tensor]:
"""
Convert an ObjectDetectionTarget_impl into a dictionary expected internally by
raw `update` method of raw torchmetrics method
"""
out = {
"boxes": torch.as_tensor(target.boxes),
"scores": torch.as_tensor(target.scores),
"labels": torch.as_tensor(target.labels),
}
return out
def update(
self,
pred_batch: Sequence[od.TargetType],
target_batch: Sequence[od.TargetType],
metadata_batch: Sequence[od.DatumMetadataType],
) -> None:
# Convert to natively-typed from of preds/targets
preds_tm = [self.to_tensor_dict(pred) for pred in pred_batch]
targets_tm = [self.to_tensor_dict(tgt) for tgt in target_batch]
self._tm_metric.update(preds_tm, targets_tm)
def compute(self) -> dict[str, Any]:
return self._tm_metric.compute()
def reset(self) -> None:
self._tm_metric.reset()
mAP_metric: od.Metric = WrappedTorchmetricsMetric(
tm_metric, metadata={"id": "torchmetrics_map_metric"}
)
Procedures#
Now we’ll run MAITE’s evaluate procedure, which manages the process
of applying the model to the dataset (performing inference) and
computing the desired metric.
# Run evaluate over original (clean) dataset
results, _, _ = evaluate(model=model, dataset=dataset, metric=mAP_metric)
# Report mAP_50 performance
results["map_50"]
0%| | 0/4 [00:00<?, ?it/s]
tensor(0.3713)
Augmentations#
The evaluate procedure takes an optional augmentation to allow
measuring performance on a perturbed (degraded) version of the dataset.
This is useful for evaluating the robustness of a model to a natural
perturbation like noise.
In this section we’ll wrap an augmentation from the Kornia library and re-run the evaluation.
First we create the “native” Kornia augmentation:
kornia_noise = K.RandomGaussianNoise(
mean=0.0,
std=0.08, # relative to [0, 1] pixel values
p=1.0,
keepdim=True,
)
Next we wrap it as a MAITE od.Augmentation, with a __call__
method that operations on batches:
class WrappedKorniaAugmentation:
def __init__(self, kornia_aug: Any, metadata: AugmentationMetadata):
self.kornia_aug = kornia_aug
self.metadata = metadata
def __call__(
self,
batch: tuple[
Sequence[od.InputType],
Sequence[od.TargetType],
Sequence[od.DatumMetadataType],
],
) -> tuple[
Sequence[od.InputType], Sequence[od.TargetType], Sequence[od.DatumMetadataType]
]:
# Unpack tuple
xb, yb, metadata = batch
# Type narrow / bridge input batch to PyTorch tensor
xb_pt = [torch.as_tensor(xb_i) for xb_i in xb]
assert xb_pt[0].ndim == 3, "Input should be sequence of 3d ArrayLikes"
# Apply augmentation to batch
# Return augmentation outputs as uint8
# - NOTE: assumes input batch has pixels in [0, 255]
xb_aug = [
(self.kornia_aug(xb_pti / 255.0).clamp(min=0.0, max=1.0) * 255.0).to(
torch.uint8
)
for xb_pti in xb_pt
]
# Return augmented inputs and pass through unchanged targets and metadata
return xb_aug, yb, metadata
noise: od.Augmentation = WrappedKorniaAugmentation(
kornia_noise, metadata={"id": "kornia_rnd_gauss_noise"}
)
For an initial test, we manually create an input batch and perturb it with the wrapped augmentation:
# Create batch with sample image
i = 0
x, y, md = dataset[i]
x = torch.as_tensor(x)
xb, yb, mdb = [x], [y], [md]
# Apply augmentation
xb_aug, yb_aug, mdb_aug = noise((xb, yb, mdb))
# Get predictions for augmented batch (which just has one image for this example)
preds_aug = model(xb_aug)
# Overlay detections on image
xb_aug = torch.as_tensor(xb_aug[0])
img_aug = create_pil_image(xb_aug, preds_aug[0], index2label)
# Show result
fig, ax = plt.subplots()
ax.axis("off")
ax.set_title("Perturbed")
ax.imshow(img_aug);

We see that the noise has resulted in some errors.
Finally, we run evaluate with the augmentation over the dataset:
# Run evaluate over perturbed dataset
results, _, _ = evaluate(
model=model,
dataset=dataset,
metric=mAP_metric,
augmentation=noise,
)
# Report mAP_50 performance
results["map_50"]
0%| | 0/4 [00:00<?, ?it/s]
tensor(0.2208)
We see that the mAP_50 performance has decreased due to the simulated image degradation.
Interop#
MAITE contains wrappers for common third-party libraries such as TorchMetrics in its interop package, e.g,
maite.interop.metrics.torchmetrics.TMDetectionMetric
When a wrapper is available in MAITE (or another source, e.g., the NRTK library for natural perturbations), we recommend using it for both convenience and reliability instead of “manually” writing a wrapper from scratch.
Here we run evaluate again on the clean data using the TorchMetrics
wrapper from MAITE interop and get the same result as above:
# Wrap native metric using wrapper from MAITE interop
metadata: MetricMetadata = {"id": "torchmetrics_map_metric"}
interop_mAP_metric: od.Metric = TMDetectionMetric(tm_metric, metadata=metadata)
# Run evaluate over perturbed dataset
results, _, _ = evaluate(
model=model,
dataset=dataset,
metric=interop_mAP_metric,
)
# Report mAP_50 performance
results["map_50"]
0%| | 0/4 [00:00<?, ?it/s]
tensor(0.3713)
Congrats! You have now successfully used MAITE to wrap a dataset, model, metric, and augmentation from various libraries, and run an evaluation to compute the performance of the pretrained model on both clean and perturbed versions of the COCO validation subset.